



Recommendation systems are a type of machine learning algorithm that is designed to predict what a user might be interested in and present them with personalized recommendations. These systems are commonly used in a variety of applications, such as e-commerce websites, streaming platforms, and social media sites. Among a variety of recommendation algorithms, data scientists need to choose the best one according to a business’s limitations and requirements. Here is an overview of the main approaches to face the problem of relevant content recommendation.
Content-based Recommendations
Content-based recommendation systems are a type of recommendation system that make recommendations based on the characteristics of the items being recommended. These systems are commonly used in applications such as e-commerce websites, where users are presented with recommendations for products based on their past purchases or interactions with the site. One way that content-based recommendation systems work is by analyzing the metadata associated with each item in the dataset. This metadata might include things like the title, description, or tags associated with the item. The recommendation system uses this information to identify the main themes or topics of each item and uses these themes to make recommendations to users. For example, if a user frequently purchases books about science fiction, a content-based recommendation system might recommend other books about science fiction that have similar themes or authors. Similarly, if a user frequently watches romantic comedies, the recommendation system might recommend other romantic comedies with similar actors or plotlines.
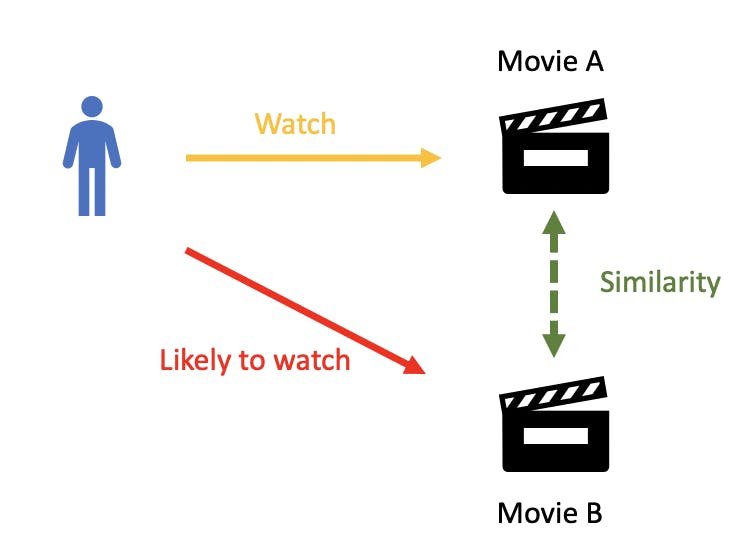
Another way that content-based recommendation systems work is by using ML algorithms to analyze the characteristics of each item in the dataset. These algorithms might consider factors such as the language used in the item's description, the tone of the item, or the presence of certain keywords. By analyzing these characteristics, the recommendation system can make more accurate recommendations to users based on their interests and preferences.
The key factor here is the way how similarity between representations of the content vectors is defined, usually, cosine similarity, dot-product, or euclidean distance are used.
Collaborative filtering (CF)
Collaborative filtering (CF) is a type of recommendation system that makes recommendations based on the past behavior of similar users. These systems work by analyzing the interactions of a group of users with a set of items, such as movies, books, or music, and using this information to make recommendations to individual users.
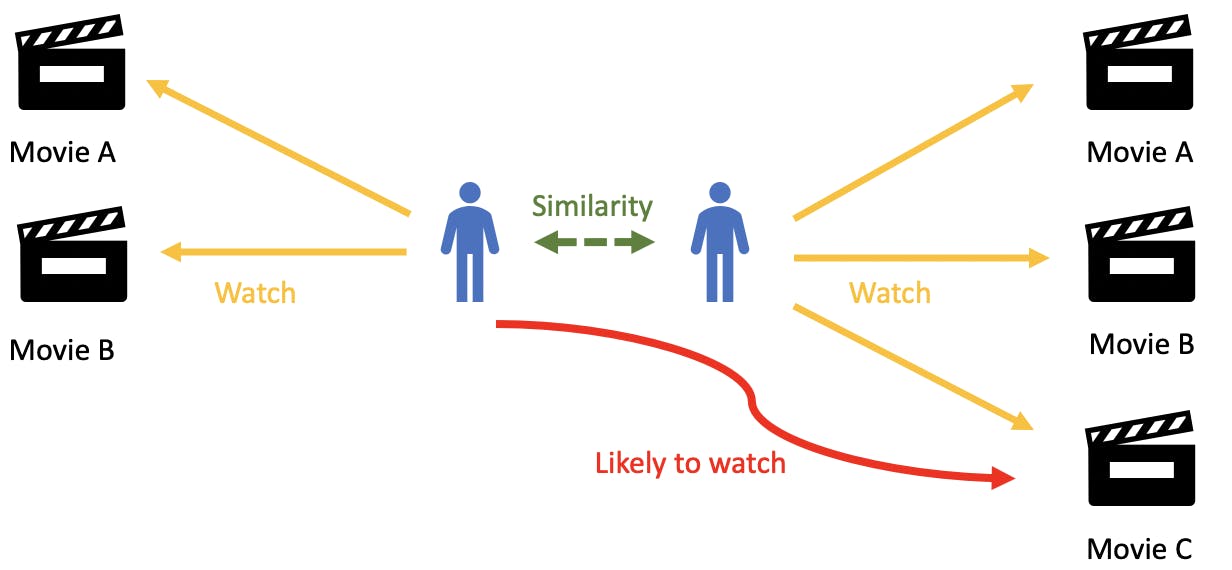
There are two main types of collaborative filtering:
user-based collaborative filtering
item-based collaborative filtering
User-based collaborative filtering works by finding users who have similar tastes and behavior patterns and using their past interactions with items to make recommendations to a specific user. For example, if two users both frequently watch romantic comedies and have similar ratings for those movies, the system might recommend a particular romantic comedy to one of the users based on the other user's positive rating.
Item-based collaborative filtering works by finding items that are similar to each other and using the past interactions of a specific user with one item to make recommendations for similar items. For example, if a user frequently listens to a particular artist and the recommendation system knows that this artist is similar to another artist, it might recommend the second artist to the user.
Both user-based and item-based collaborative filtering can be effective at providing personalized recommendations to users, but they each have their own unique set of strengths and limitations. User-based collaborative filtering is generally more effective at making recommendations for users with a limited history of interactions, while item-based collaborative filtering is generally more effective at making recommendations for items with a limited number of interactions.
Matrix Factorization Algorithms
Matrix factorization algorithms are a type of recommendation system that use mathematical techniques to decompose large matrices of user-item interactions into a set of latent features that can be used to make recommendations. These algorithms are commonly used in applications such as streaming platforms and e-commerce websites, where they can be used to make personalized recommendations to users based on their past interactions with the platform.
There are several different types of matrix factorization algorithms, each with its own unique set of characteristics and capabilities, there are 3 most popular methods to choose from:
singular value decomposition (SVD)
observed only Matrix Factorization
weighted Matrix Factorization
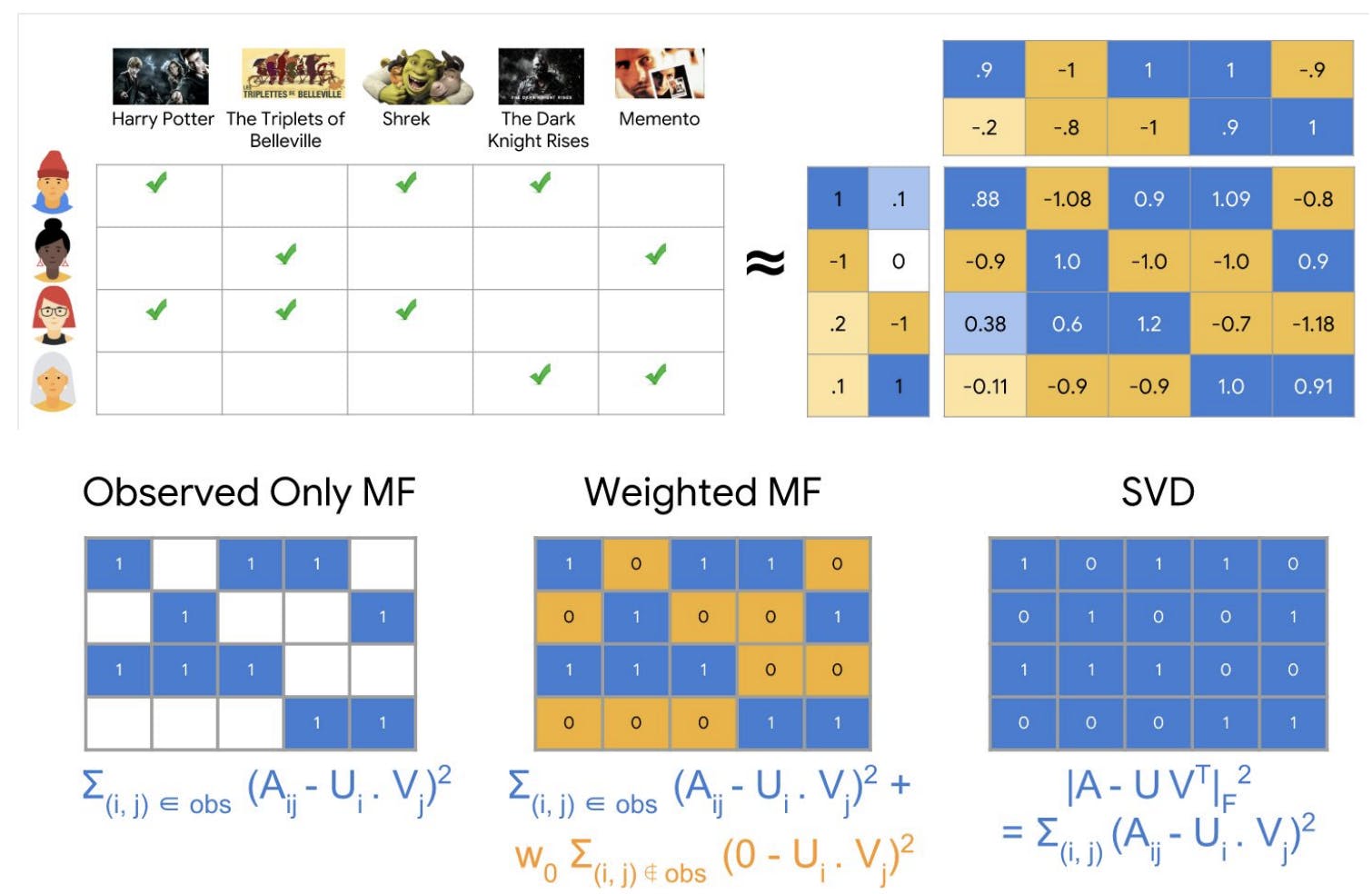
Each of these methods proceeds the optimization of the target matrix A under different assumptions about unobserved fields (when a user didn't interact with an item). Another question that should be defined at the start: is how exactly the positive interaction is defined. On e-commerce websites, it can be a successful purchase but on video-streaming platforms, users may never watch the whole video until the end, the way the positive, neutral, and negative experiences are defined, highly impacts the final results.
Context Incorporation
Recommendation systems that incorporate context are a type of recommendation system that takes into account additional information about the user or the environment in which the recommendation is being made. This can include things like the user's location, the time of day, or the user's current activity. By incorporating this additional context, these recommendation systems can provide more personalized and relevant recommendations to users.
For example, a recommendation system for a restaurant app might use the user's location to suggest restaurants that are within a certain distance of the user's current location. Another way that recommendation systems incorporate context is by using time information to provide recommendations for items or activities that are appropriate for the current time of day. For example, a recommendation system for a streaming platform might use the time of day to suggest movies or TV shows that are appropriate for the user's current mood or activity level.
There are 3 main possible options for how to work with the context:
contextual prefiltering
contextual post-filtering
context modeling
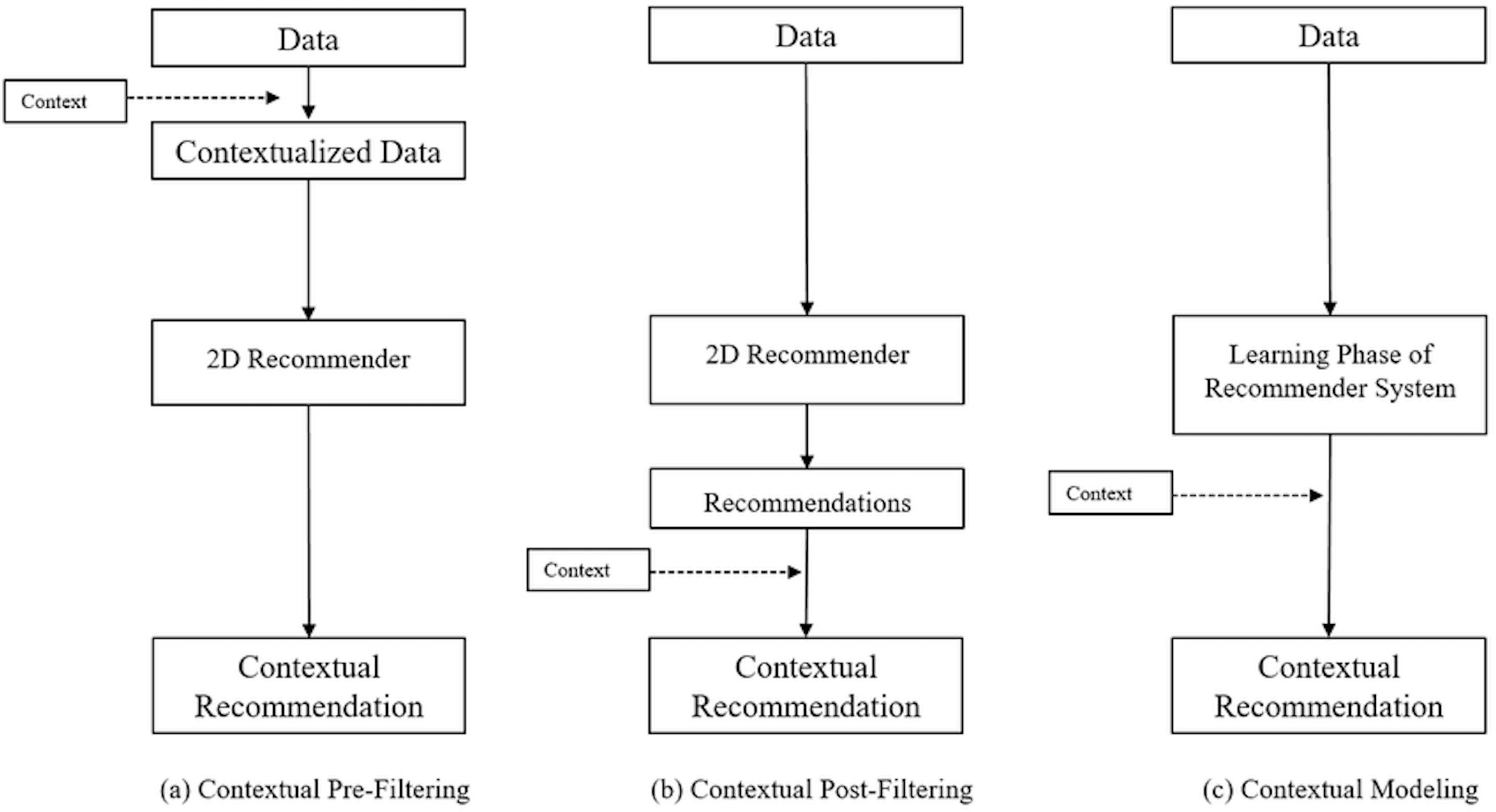
In the prefiltering option we are reducing our 3D interaction space from (User, Item, Context) to (User, Item) by selecting only the current context in 3rd dimension. In the post-filtering option, we simply ignore the context and work with 2D interaction space (User, Item). At the stage of candidate generation, we apply the context filtering rules and leave only the candidates that are relevant within this context. In the context modeling option, we try to add bias terms for global average rating, average item rating, average user rating, etc.
Hybrid Recommendation Systems
Hybrid recommendation systems are a type of recommendation system that combine the strengths of multiple recommendation approaches to provide more accurate and diverse recommendations to users.
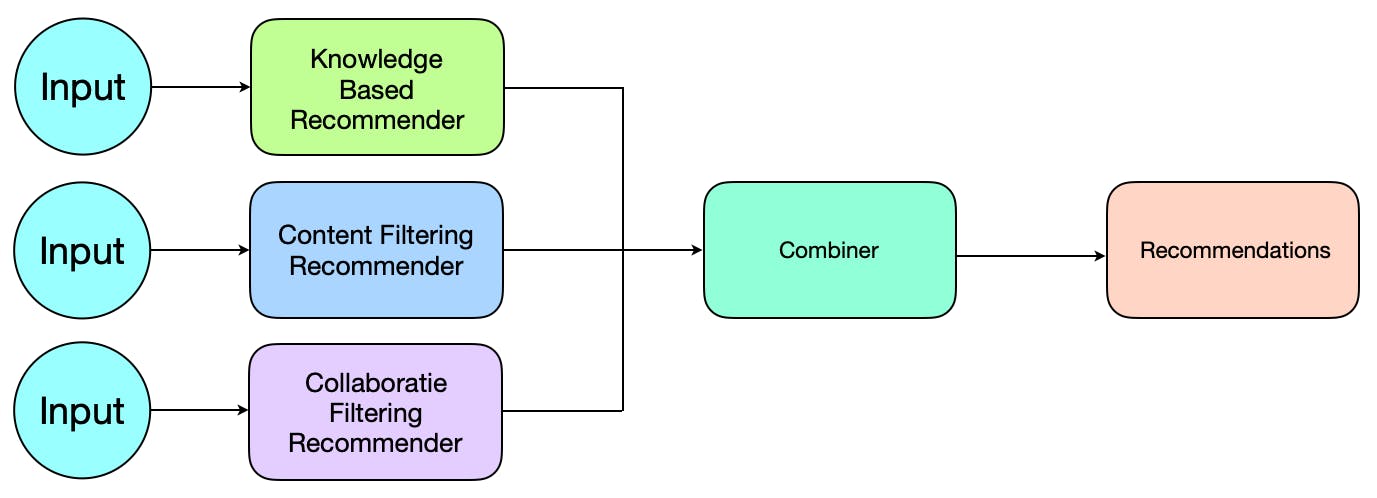
The cold start problem is the very common obstacle after the new Recommendation System was launched. Finding the right balance between various algorithms outputs helps to partially resolve this problem for new users and new items. By combining the strengths of multiple recommendation approaches, these systems can provide more accurate and engaging recommendations than any single approach alone.
Recommendation System Pipeline
A recommendation system pipeline is a series of steps or stages that are followed in order to build a recommendation system. The steps in a recommendation system pipeline can vary depending on the specific needs and goals of the recommendation system, but some common steps include candidate generation and ranking. They may be additional substeps in the pipeline like re-ranking after introduction of additional context but we are considering the main idea here.
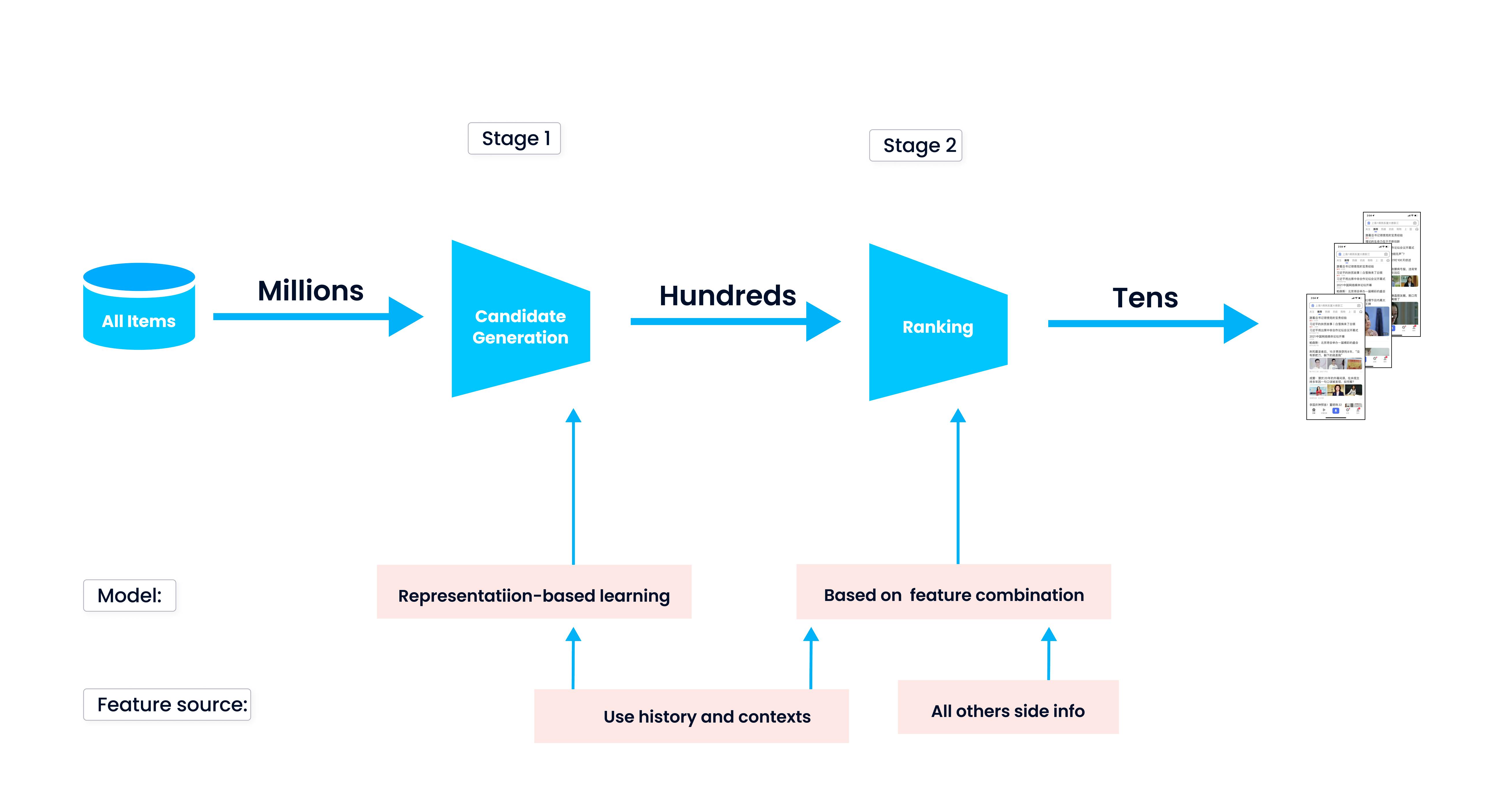
Candidate generation is the process of identifying a set of items that are candidates for recommendation to a specific user. This can involve using techniques such as collaborative filtering or content-based recommendation to identify items that are similar to items that the user has previously interacted with, or it can involve using machine learning algorithms to identify items that are likely to be of interest to the user based on their past behavior or characteristics. The specifics of this step is the high speed of the algorithms. We care about recall by trying to select as more potentially relevant candidates from millions or even billions as possible.
Ranking is the process of ordering the candidates identified in the candidate generation step by their predicted likelihood of being of interest to the user. This can involve using machine learning algorithms to predict the ratings or interactions that the user is likely to have with each item, or it can involve using other techniques such as collaborative filtering or content-based recommendation to identify the most similar or relevant items. The specifics of this step is the more complex evaluation of the candidates for better ordering. We care about precision by selecting top-N candidates that will be recommended to the final user.
Metrics
There are several different metrics that are commonly used to evaluate the performance of machine learning recommendation systems. Along with the standard quality metrics, there are some metrics especially for recommendation problems: Recall@k and Precision@k, Average Recall@k, and Average Precision@k. Also, look at the great description of metrics for recommendation systems. Offline and online metrics for system evaluation are different: you may evaluate the candidate generation step with recall-type metric, and the ranking step with precision-type metric or NDCG. However, business metrics usually relate to overall user engagement of the system or different key business goals. The problem that may appear in such cases is called Misaligned metrics, where a positive impact on offline metrics doesn't necessarily lead to online business metrics improvement. During this article each stage included multiple hyperparameters that can be tuned, this situation is their finest hour.