AutoML Python packages

Machine Learning Engineer at Amazon Alexa Shopping (London) Ex-Microsoft Data Scientist MSc Computer Science
Introduction
AutoML, or Automated Machine Learning, is a growing field in artificial intelligence focused on making Machine Learning more accessible to non-experts. AutoML aims to automate some of the most time-consuming and complex tasks involved in building and deploying machine learning models, such as feature engineering, algorithm selection, and hyperparameter tuning. Many ML/DL engineers can agree that this process can be boring after going through the same stages each time in a new project.
The idea behind AutoML is to create a set of tools that can automate the entire ML process, from data preparation and model selection to training, testing, and deployment. The ultimate goal is to make machine learning more accessible and easier to use, so businesses and organizations of all sizes can benefit from the insights and predictive capabilities that it provides. This can be especially valuable for businesses that have limited resources or that lack the expertise to build and maintain their own ML infrastructure.
This field has been developing for a couple of years now and there are many AutoML packages and libraries available that can help automate the ML processes. We will review the most popular of them today.
AutoML Packages
AutoKeras
It is a popular open-source AutoML library in Python that allows users to easily build and train deep learning models without requiring deep expertise in the field. The library can be installed as a Python pip package and requires Python >= 3.7 and TensorFlow >= 2.8.0. As can be understood from the name, the library uses Keras framework under the hood.
AutoKeras automates the process of model selection, hyperparameter tuning, and architecture search. It uses a technique called neural architecture search (NAS) to automatically find the best architecture for a given task. It is a process of searching for the best neural network architecture by evaluating multiple candidate architectures, either randomly or based on some predefined strategy. The library supports a variety of tasks such as image classification, regression, text classification, structured data classification, and time series forecasting. It also includes pre-processing modules for data augmentation, normalization and feature engineering.
The example of usage of this library is relatively short thanks to the intuitive but limited API. Depending on the task you have to create the instance class of the optimizer:
#for images
img_clf = autokeras.ImageClassifier(max_trials=10, num_classes=10)
img_reg = autokeras.ImageRegressor(overwrite=True, max_trials=1)
#for texts
text_clf = autokeras.TextClassifier(overwrite=True, max_trials=1)
text_reg = autokeras.TextRegressor(overwrite=True, max_trials=10)
#for structured data
str_clf = autokeras.StructuredDataClassifier(overwrite=True,
max_trials=3)
str_reg = autokeras.StructuredDataRegressor(overwrite=True,
max_trials=3)
max_trials means the maximum number of models to experiment with. AutoKeras provides some customization of neural architecture search, so you can specify in which types of architectures you want to run the search, for example, only ResNets:
input_node = autokeras.ImageInput()
output_node = autokeras.ImageBlock(
# Only search ResNet architectures.
block_type="resnet",
normalize=False,
augment=False,
)(input_node)
output_node = autokeras.RegressionHead()(output_node)
regr = autokeras.AutoModel(inputs=input_node, outputs=output_node,
overwrite=True, max_trials=1
)
After the model type is specified, the only thing you should care about while running NAS is the number of epochs per each hypothesis:
img_clf.fit(X_train, y_train, validation_data=(X_val, y_val))
_, acc = img_clf.evaluate(X_test, y_test)
Overall, AutoKeras is a powerful library for a very fast model building for a standard list of tasks. Let's summarize with some specific Pros and Cons of AutoKeras:
Pros
Automatization: it automates the model selection, hyperparameter tuning, and architecture search process;
Flexibility: it supports a variety of tasks, including image classification, regression, text classification, structured data classification, and time series forecasting;
Speed: it can quickly search a large space of possible models and hyperparameters, enabling users to build and train models faster than they could manually;
Cons
Limited customization: while the library is flexible, it is not as customizable as manually writing deep learning code. You may find it difficult to implement custom loss functions, and layer types;
Resource intensity: it can be resource-intensive, particularly when searching a large space of models and hyperparameters;
Black box: inner workings of the library are hidden from users, the architecture search process in particular. It may be difficult to understand why AutoKeras selects a particular model or set of hyperparameters.
AutoGluon
AutoGluon is another open-source library for automated machine learning (AutoML) developed by the Amazon Web Services (AWS) team. Apart from the NAS that we discussed for AutoKeras, this library includes a feature called "stacking," which combines multiple ML/DL models to improve the overall accuracy of predictions. Stacking involves training several models on the same dataset and then using their predictions as inputs to another model, which outputs the final predictions.
Another feature is that AutoGluon includes built-in support for distributed training, which allows users to train models on multiple machines for improved performance. This is not very visible by searching on your local machine but it can become a key advantage if you run the NAS in the cloud infrastructure. The setup for distributed search is pretty straightforward, the number of available resources should be specified with the addresses to remote machines:
extra_node_ips = ['172.31.3.95']
scheduler = ag.scheduler.FIFOScheduler(
train_fn,
resource={'num_cpus': 2, 'num_gpus': 1},
dist_ip_addrs=extra_node_ips)
scheduler.run(num_trials=20)
scheduler.join_jobs()
AutoGluon also supports a wider range of tasks compared to AutoKeras, for example, Interpretable rule-based models, Feature engineering for tabular data, and Object detection tasks. The library provides some customization of the model search during the optimization with a wide range of hyperparameters, in addition to it you can predefine the search space for NAS via library API.
A simple example for text classification model will look like this:
import uuid
from autogluon.core.utils.loaders import load_pd
from autogluon.multimodal import MultiModalPredictor
# data with 2 columns 'sentence' for text and 'label' for label
train_data = load_pd.load('PATH_TO_DATA')
test_data = load_pd.load('PATH_TO_DATA')
model_path = f"./tmp/{uuid.uuid4().hex}-automm_sst"
predictor = MultiModalPredictor(label='label', eval_metric='acc', path=model_path)
# here we limit each trial with time unlike number of models max_trials in AutoKeras
predictor.fit(train_data, time_limit=180)
test_score = predictor.evaluate(test_data, metrics=['acc', 'f1'])
test_predictions = predictor.predict(test_data)
All of the trained models are serialized and saved for deployment. Library has a very powerful documentation with a search bar, cheat sheets for multiple tasks and very active community of developers on github.

Let's summarize with some specific Pros and Cons of AutoGluon:
Pros
Full automation: AutoGluon automates many aspects of ML/DL model development (feature engineering, feature analysis, hyperparameter tuning, NAS);
State of the art models: AWS team constantly improves the package and integrates the most recent models and approaches for efficient NAS.
Cons
Limitations: library doesn't cover all tasks, only the most popular ones (Tabular/Image/Text prediction, object detection and NAS) but still it covers many tasks or at least components in the ML pipelines;
Computational Resources: Autogluon is designed primary to take advantage of distributed computing, it may require significant computational resources to run effectively. This can be a barrier for smaller organizations or individuals with limited computing resources.
AutoSklearn
It's built on top of the popular machine learning library scikit-learn. AutoSklearn frees a developer from algorithm selection and hyperparameter tuning. It leverages recent advantages in Bayesian optimization, meta-learning and ensemble construction (NIPS paper from team). This is one of the most limited but at the same time the fastest ways to test multiple models on your dataset. The library doesn't require any ML knowledge and provides a straightforward API. The simplest example of usage can be covered with only 4 lines of code:
import autosklearn.classification
automl = autosklearn.classification.AutoSklearnClassifier()
automl.fit(X_train, y_train)
y_pred = automl.predict(X_test)
# for fitted models leaderboard
automl.leaderboard()
More examples for the library usage can be found in the github repository. It's worth mentioning that the library already moves towards the direction of finetuning of custom models. For the MLP, for example, you can define the hyper parameter search space and take advantage of optimal optimization strategies of the AutoSklearn (compared to the brutforce hyper parameter tuning).
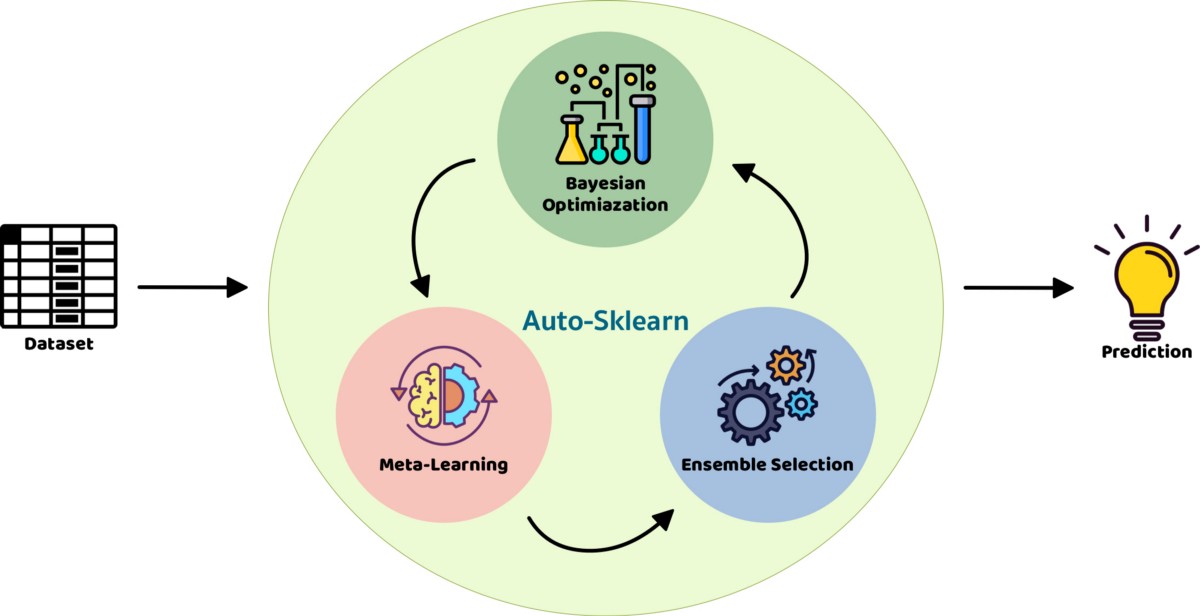
To sum up with this library I want to focus on specific Pros and Cons:
Pros
- Straightforward usage: the API of the library is very simple. As we have seen in the example, you don't need to know anything from ML/DL theory to run the training, 4 lines of code are enough to get quick results;
Cons
- Quiet obvious that the library focuses mainly on scikit-learn package models. If you have more complex tasks which scikit-learn library are not able to solve, use AutoKeras or AutoGluon depending on your requirements and resources.
TPOT
The last but not least library that we cover in this article is TPOT. The library automates the process of building Machine Learning pipelines using genetic programming. It aims to automate the most tedious part of ML by exploring thousands of possible pipelines to find the best one for your data.
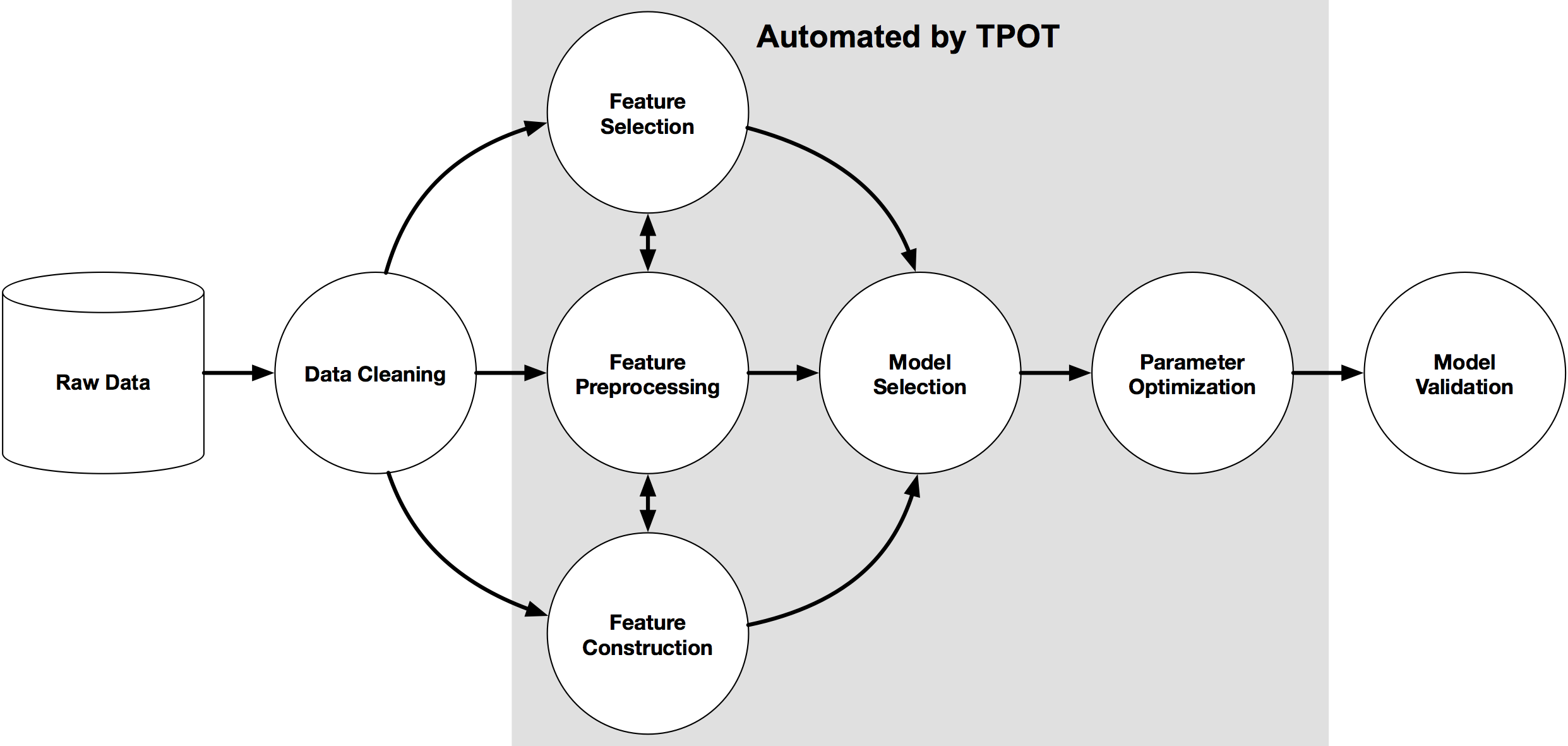
The genetic programming approach draws inspiration from Darwin's concept of natural selection and involves the following properties:
Selection: In this stage, each individual's fitness function is evaluated and normalized so that each individual has a value between 0 and 1, and the sum of all values is 1. Next, a random number between 0 and 1 is chosen. Individuals with fitness function values greater than or equal to the chosen number are retained;
Crossover: The fittest individuals retained in the previous stage are then selected, and a crossover operation is performed between them to generate a new population;
Mutation: The individuals generated by crossover are subjected to random modifications, and the process is repeated for a specified number of steps or until the best population is obtained.

The library is built on top of scikit-learn and uses similar interface for training and testing the models. TPOT supports both classification and regression tasks, and includes a wide range of pre-built machine learning operations, such as scaling, imputation, feature selection, and model selection. It also allows users to specify their own custom operations, giving them greater flexibility in designing pipelines. The minimal working example for classification task is similar to AutoSklearn:
from tpot import TPOTClassifier
tpot = TPOTClassifier(generations=10, population_size=50, random_state=5)
tpot.fit(X_train, y_train)
print(tpot.score(X_test, y_test))
More advanced examples and use cases can be found on the TPOT github. Library allows to specify your own models in the pipeline as well as feature generation steps for your data if you want to fix this step. To sum up with this library I want to focus on specific Pros and Cons:
Pros
- TPOT uses genetic programming to search through a space of possible pipelines and hyperparameters, in order to find the best combination for a given dataset and task. This can result in significantly improved model performance compared to manually-tuned pipelines;
Cons
- TPOT has limited model compatibility, at the moment only sklearn library models can be used for pipeline optimization
Conclusion
In conclusion, AutoML packages provide automated solutions for building, optimizing, and deploying machine learning models. These packages can save significant time and effort for machine learning practitioners by automating tedious and time-consuming tasks such as hyperparameter tuning, feature selection, or model architecture selection.
Each of the AutoML packages uses variant optimization schemes, offers a different list of models for the pipelines, enables various types of customization, and provides distributed search opportunities. There is no silver bullet for all tasks and all needs, you should choose the most suitable package depending on your task and available resources. With the help of AutoML packages, ML/DL Engineers can focus more on high-level aspects of the problem and less on the low-level details of building and optimizing models.



